Parallel Computing
Improving response time in dynamic and concurrent DAG scheduling on heterogeneous systems
Heterogeneous Systems are characterized by having a variety of different types of computational units and are widely used for executing parallel
applications, especially scientific workflows. The workflow consist of many tasks with logical or data dependencies that can be dispatched to
different computation nodes of the heterogeneous system.
The aim of this project is to improve the response time of a system when managing independent user jobs described by Direct Acyclic Graphs (DAGs).
we develop algorithms for dynamic application scheduling that focus on the Quality of Service (QoS) experienced by each application (or user).
The aim is to reduce the waiting and execution times of each individual workflow.
An example is given below, where there is no static allocation of processors to jobs so that the system scheduler can improve the
resource usage without compromising individual job processing time.
Dynamic scheduling of mixed parallel task jobs on heterogeneous clusters
This work addresses the problem of minimizing the scheduling length (make-span) of a batch of jobs with different arrival times.
A job in this context is described by a direct acyclic graph (DAG) of parallel tasks. We developed a dynamic scheduling method that
adapts the schedule when new jobs are submitted and that may change the processors assigned to a job during its execution. The
scheduling method is divided into a scheduling strategy and a scheduling algorithm.
The strategy defines which tasks are considered when scheduling, as shown in the following figure:

The scheduling algorithm can be selected from a set of algorithms, as shown by the next figure:

The aim is to minimize the completion time of a batch of jobs, which corresponds to many real-world applications such as video surveillance,
microscopic imaging processing, biomechanical analysis and image registration.
An example of image registration for 3D object reconstruction is shown in the figure below. The method consists of defining the target object by its
border in each frame and, between each two frames, a deformable object tracking algorithm is computed to find the corresponding points in two consecutive
frames. The figure shows the first and last frames of a sequence of 21 images taken from a CT scan of a human trunk. The object segmented is the left lung.

Mixed parallel task scheduling
Mixed parallel tasks, also called malleable tasks, are tasks that can be executed on any number of processors with its execution time being a function of the number of processors alloted to it.
An example is given below, where there is no static allocation of processors to jobs so that the system scheduler can improve the
resource usage without compromising individual job processing time.
For arbitrary precedence graphs and for heterogeneous machines, the optimization problem is more complex because the processing
time of a given task depends on the number of processors and on the total processing capacity of those processors.
In this project it was developed a list scheduling algorithm to minimize the total length of the schedule (makespan) of a given set of
parallel tasks, whose dependencies are represented by a DAG. The algorithm is called
To overcame the heterogeneity of the machine, HPTS starts by computing the amount of capacity in Mflops, instead of number of
processors, that minimizes the processing time of each task. For that it uses the fastest processors and determines the minimum
processing time that each task can achieve in that machine. Then, the algorithm joins processors until the maximum capacity required
for each task is achieved, independently of the number of processors, but restricted by the maximum capacity available.
The algorithm proposed does not require a static subdivision of processors. When scheduling a set of ready tasks the machine is viewed
has a whole, independently of the groups of processors formed in the last level, thus allowing a better use of the machine and
consequently achieving improvements in processing time.
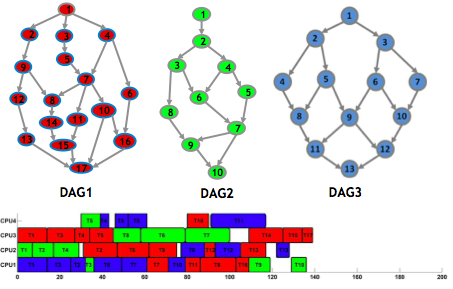
The figure below shows an example of the schedule obtained with HPTS. The main characteristic is that the algorithm finds the best
configuration of processors for each task and optimizes the total execution time of the job. Unlike previous work it can schedule any
time of DAGs.

Data distribution strategies for LU factorization on heterogeneous clusters
LU factorization is an inherently sequential algorithm that is characterized by the fact that the computation of a given data element requires
knowledge of the results obtained in previously processed elements, and there is a predefined pattern of computation. To achieve higher speedups the
data distribution algorithms must take this characteristic into account. The LU algorithm has an important characteristic that is the number of
required flops to compute each column depends on their position (or index), as illustrated in the next figure:

Therefore new data distribution strategies are required for heterogeneous systems. The Group Block distribution that we developed showed to outperform
the state of the art distributions as shown by the following figure, for heterogeneity factors above 0.3:

Dense linear algebra kernels for heterogeneous machines
In this work a set of linear algebra kernels was adapted to run efficiently on heterogeneous systems. A computational model and a methodology was developed in order to schedule the data blocks to processors so that the processing time is minimized. The algorithms considered were matrix multiplication, LU factorization, tridiagonal reduction and symmetric QR factorization.